

The mid-2010s were an exciting time for data science. Big data technologies like Hadoop and Spark were being adopted at scale, cloud computing was making unprecedented computational power accessible, and the field of machine learning was advancing rapidly. Just as every forward-thinking company was racing to adopt big data and machine learning, excitement about a bold new promise emerged: AutoML, or Automated Machine Learning.
The idea behind AutoML is conceptually simple: if you know what you’re trying to predict (like fraud or churn), then isn’t building the very best ML model just a giant optimization problem? Can’t the entire machine learning loop be automated?
Google Trends show how popularity in the idea exploded in late 2017:
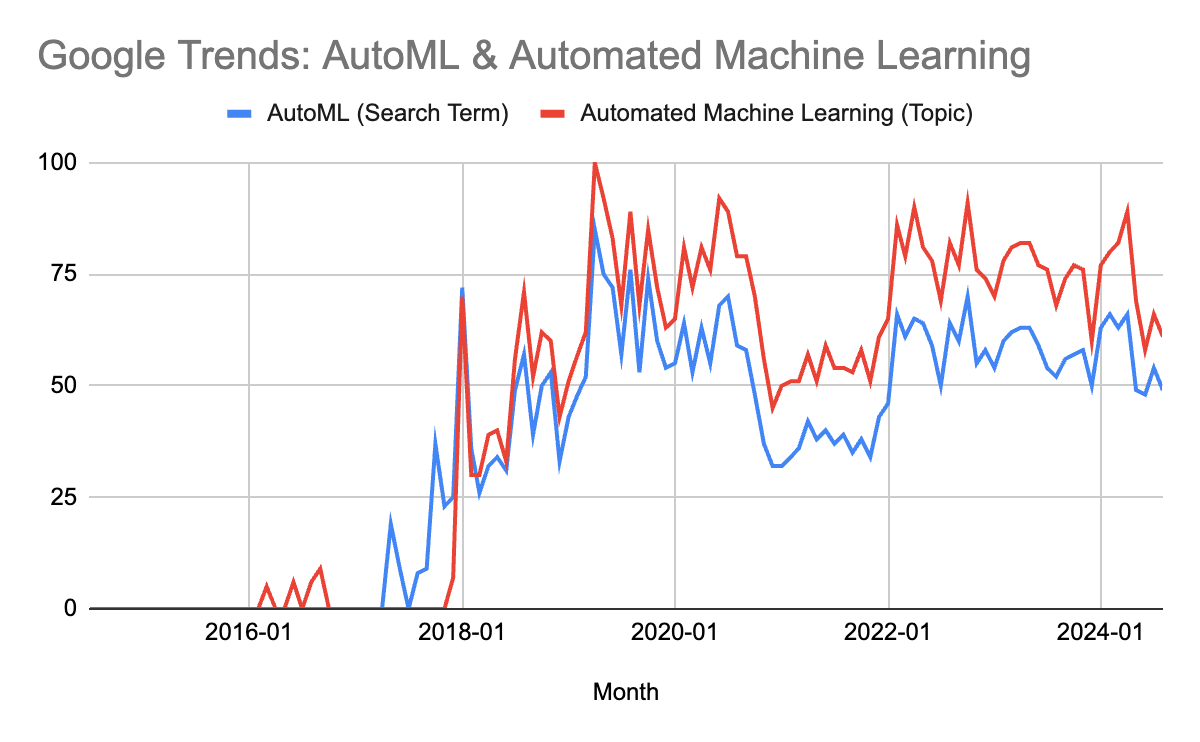
The vision of AutoML was understandably appealing: automating ML itself would allow companies to leverage the power of machine learning without needing teams of expensive, hard to hire, hard to manage data scientists.
Yet AutoML didn't revolutionize data science as promised; and in fact, there is generally a sense of skepticism about AutoML in the data community. You can see in the Google Trends that the popularity of AutoML today is below its peak in 2019.

During our time at Uber, we used AutoML to help with hyperparameter tuning. We’ve seen real wins — it definitely creates value. But ultimately, we’ve come to think of AutoML as helping with only the final 10% of building models.
Don’t get us wrong, that last 10% is important! And yet, that 10% is far from enough to obviate the need for data science teams. And when we talk to data scientists, a surprising number of them actually still tune their models by hand.
So what, exactly, went wrong?
Where AutoML fell short
1. AutoML doesn't solve the hardest problems
The most glaring issue with AutoML is that it is a misnomer: it focuses on a sliver of the ML workflow and skips the hardest parts of ML altogether.
At Delphina, we think about the ML process in four steps: problem framing, data prep, building models, and deployment. AutoML tools primarily focus on a narrow set of tasks within the third “build” step, mostly around choosing, training, and tuning the model.
Specifically, most AutoML tools expect you to feed in a flat dataframe or CSV of data that includes a column you want to predict, and then they will try lots of different model types and hyperparameter configurations to best predict that outcome.
Again, this is helpful – but data scientists spend the majority of their time on other tasks, largely before model selection and building. For example, Anaconda’s 2022 survey of the state of data science found that data scientists only spend 18% of their time on model selection and training. The lion’s share goes to other work like:
- Problem framing: The first step to impactful ML projects is making sure you're solving the right problem. If you don’t get this right, it’s easy to waste months of work and fail to deliver value.
- Finding the right data in a large relational warehouse: Data scientists must painstakingly navigate through hundreds or thousands of data fields, often with confusing naming conventions and unclear ownership.
- Understanding and cleaning that data: Once the right data is located, it needs to be reshaped and cleaned. This involves deciphering how the data was created and handling various data quality issues.
 Photo by Pierre Bamin on Unsplash
Photo by Pierre Bamin on Unsplash
AutoML tools focus on the cleanest part of the workflow — the constrained space of optimizing what data they've been given – and leave data scientists to manually grapple with the rest.
2. AutoML is too opaque
A second significant limitation of AutoML tools is their lack of transparency. These systems produce a fitted model as their output, but they usually don't provide visibility into how they arrived at that particular model, nor make it easy to understand why it's good. This "black box" nature might be OK if the AutoML is only picking hyperparameters, but quickly becomes problematic if it’s trying to do a lot more – even simple data cleaning or column transformations.

That’s because data scientists often need to understand the guts of their models – e.g. what patterns the model is picking up on, and how those might play out in different situations. In order to make targeted improvements to models or address specific weaknesses, data scientists need visibility into what’s actually happening under the hood.
3. AutoML isn’t easy enough to use
The solution to the opacity problem is for a scientist to crack open the AutoML tool and play with the inner workings of the system. But this is easier said than done.

This creates a paradox: unless the off-the-shelf AutoML gets the job done, practitioners need to pick up an entirely new set of skills to customize it. And so data scientists proficient with libraries like XGBoost and Pandas find it easier to stick with what’s tried and true.
Where data scientists go from here
The moral of this story: in data science, you can’t “just optimize it”. There’s no magic wand that you can plug into Snowflake to instantly solve all your data problems.
AutoML can do good work with small-scale clean datasets. Give it a 1,000-row CSV file and it will produce something reasonable. But it doesn’t come close to solving the real problems that large enterprises are dealing with.
The result is that data scientists continued to do the hard work by hand — until GenAI’s abilities matured enough to start filling these gaps.
Two years on: AI data agents are doing what AutoML couldn’t
The funny thing about AutoML, looking back, is that the vision was right; the execution was just too narrow. AutoML tried to automate the tail of the ML workflow — the part that turned out to be the easiest. The hard parts — finding the right data, understanding what it means, framing the right problem, validating the answer — were left untouched.
AI data agents are now tackling exactly those hard parts. Not for the model-training task that AutoML focused on, but for the much larger class of analytical questions that businesses ask every day. Find the right tables. Read what the data means. Apply the institutional context. Run the analysis. Validate the answer against ground truth.
At Delphina, that’s the foundation: an AI-managed context layer that captures what data means, how metrics are defined, and which business rules apply — paired with AI agents that can answer analytical questions reliably, a critic agent that catches mistakes, and AI-generated evals that keep accuracy high as data evolves. It’s not AutoML 2.0. It’s a different category, attacking the problem from the other end of the workflow.
This is also why we expect data scientists to keep doing meaningful work for a long time. The hardest parts of model building still need humans. But the painstaking analytical work that consumed 80% of every data scientist’s time, and prevented business teams from ever touching their own data, is exactly what AI data agents are finally good at.
If you’ve been watching the AutoML space and wondering what came next, write us at info@delphina.ai or book a demo.