

 Image by DALL-E
Image by DALL-E
How do talented data science teams at startups manage to waste months building a model in local notebooks, only to find the data their model relies on isn’t actually available at the time of inference in production?
And why do ambitious engineering teams sometimes spin up overly complex neural networks to address a problem that would be better solved by a tree-based model?
These issues happen all the time — a crazy percentage of data and AI projects fail to make it to production.
We’ve spoken with dozens of leaders who are endlessly frustrated by the difficulties of getting data and AI projects to deliver. And we’ve seen these conflicts and inefficiencies happen firsthand.
At Uber, we spent a lot of time talking about the “data science -> engineering waterfall”. It wasn’t a happy waterfall. Calling it a sore spot was an understatement.
 Photo by Eric Muhr on Unsplash
Photo by Eric Muhr on Unsplash
At times, our data scientists would go off and build models on their own without involving engineering. They would come up with some brilliant but complicated ideas, then come back and say, “Here, engineers. Figure out how to ship this.”
This didn’t go well. Engineers felt excluded. Efficiency suffered, and projects would fail.
Over time, we explored hard cultural questions — were we a technology company, or a data science company?
In other words, our teams at Uber faced the same challenges as any organization that fails to answer a fundamental question: Who owns the work of data and AI?
This question may sound basic, but it’s vital and often overlooked. It’s uncomfortable. Data and AI are exciting and powerful, so everyone wants to own them.
It’s also deceivingly complex — the right answer is, “it depends”. The right answer differs based on the company size and even the maturity of the data and AI project itself.
Our goal today is to explore the core elements of data and AI ownership: who’s involved, who’s accountable, and how ownership shifts over time.
The skill sets of data and AI: business, modeling, and engineering
Before you can determine the right ownership for a data and AI project, you need a clear understanding of what work actually needs to be done.
Imagine you’re building a model to personalize the homepage of your website, applying ML to decide which products will be the most relevant to a prospective customer. This is a pretty standard application of ML — but think of all the decisions that need to be made along the way, the data and infrastructure needed to scale, and the different skill sets required at every step.
-
**Business: **The way you approach this personalization will depend entirely on the problem you’re trying to solve, or the outcome you want to achieve. Are you simply trying to increase revenue or focused on something more nuanced like customer lifetime value? What elements on the page will the model be able to change — variables like headlines or imagery, or the types and number of products recommended? Will business stakeholders be ok with that? How will you explain the plan to business stakeholders?
-
**Statistics and modeling: **Turning this business question (e.g., let’s see if we can increase customer lifetime value through personalized product recommendations) into a statistical model requires a mathematical and data-centric approach. You’ll need to identify what the objective function really is - how will you compute customer lifetime value (or a proxy for it)? What data should be used to power the model, how it should be cleaned and transformed, and what kinds of models will provide the best fit? You’ll also need to understand and interpret the results of your A/B tests to refine and improve results once your model goes live.
-
**Engineering and infrastructure: **Your project requires infrastructure to support the model during training and after it’s gone live, including data pipelines, model and data serving capabilities, front-end content that’s being personalized, feature flagging and experimentation. All of these systems need to be performant, maintainable, and scalable — and operate within frameworks that allow your team to iterate quickly based on the outcomes of your testing.
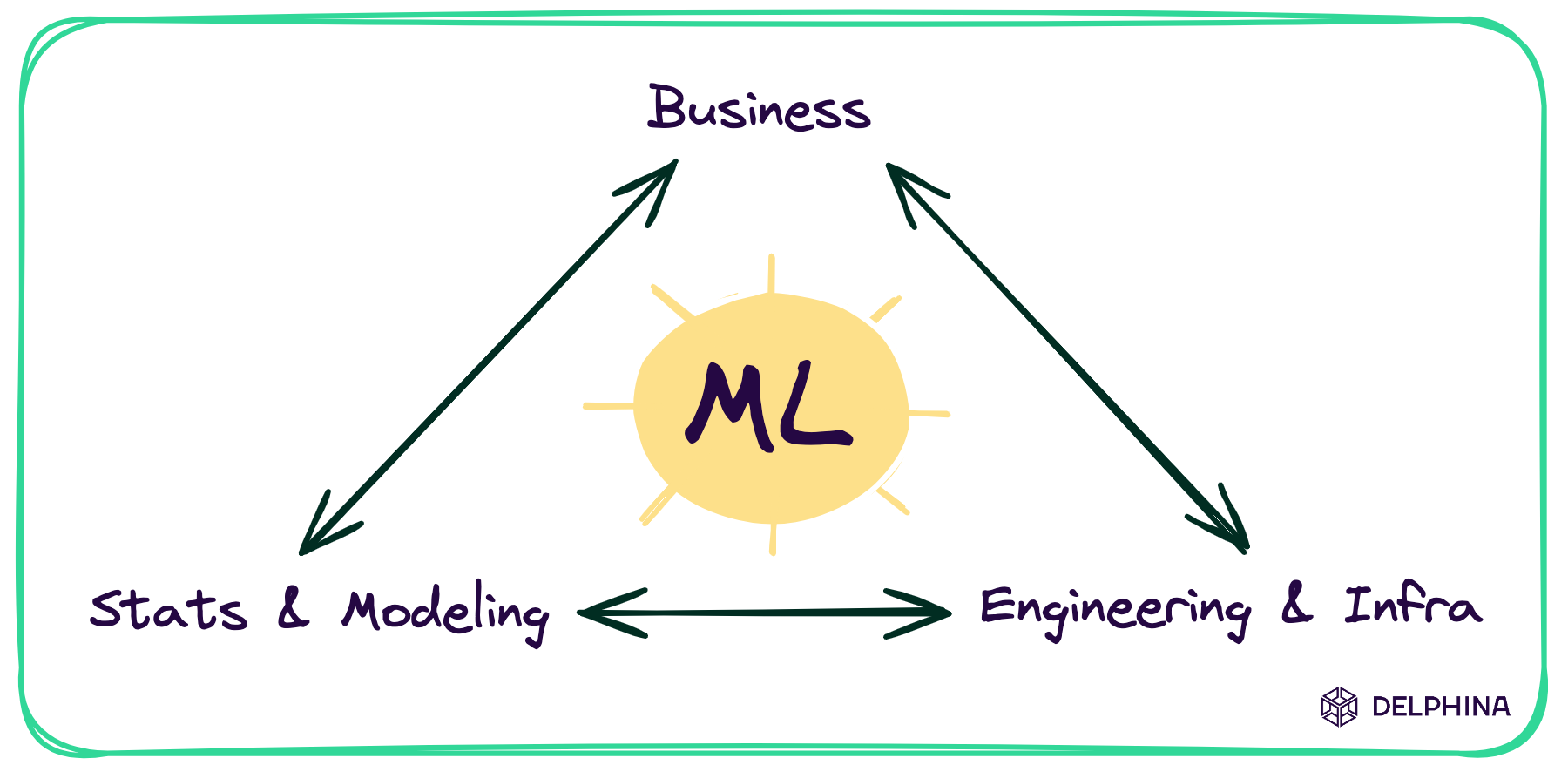
Each of these three skill sets is essential for a successful data and AI project — think of them as legs on a stool. Take one away, and the whole thing topples over.
Early on: forget improving handoffs and focus on cross-functional teams
When you’re solving a new problem, this three-legged stool requires cross-functional collaboration.
It’s next to impossible to find a single individual with the business acumen, mathematical know-how, and engineering skills to fully execute a data and AI project successfully from end to end on their own.
And while there’s a lot of talk about improving handoffs between data science and engineering, we believe that’s a misguided approach.
In these cases data and AI work should be less like a relay and more like a three-legged race. Don’t hand off a baton (or a Jupyter notebook) — get your cross-functional teams working together from the starting line.
 Image by DALL-E
Image by DALL-E
Because without collaboration across these three areas, we see painful breakdowns happen.
Data science teams can waste months building models in their local notebooks — only to find the data they need isn’t actually available at inference time. Or engineers may plow ahead on infrastructure to power an exciting, sophisticated deep learning framework without realizing that they don’t have enough data to make that framework valuable.
The truth is, business problems aren’t solved by getting one piece of this right. Rather, business problems are solved by getting all 3 of these right together. A simple model that optimizes for what the business actually cares about and is backed by the right infrastructure can work wonders.
That’s why **it’s essential to align these three functions at the earliest stages: business expertise from product management, statistical expertise from data science, and infrastructure expertise from engineering. **
Make them collectively accountable for tackling a given business problem. Have those 3 humans write a one-pager together that describes the why, the what, and the how. Have them be responsible for the plan and the delivery.
When you set these expectations from the start, cool statistics or impressive technology that doesn’t actually solve the problem won’t get a pass. But real outcomes will.
 Photo by krakenimages on Unsplash
Photo by krakenimages on Unsplash
As data and AI projects mature, ownership can shift
Once you have an initial model set up, improving the value you get out of it basically comes down to iterating on one of four things:
-
Better problem framing that refines the model to focus on tackling what the business cares about most.
-
Better data and features that increase the model’s performance by providing more, or more relevant, data.
-
**Better modeling approaches **that improve the model’s performance through improving the model itself.
-
Entirely new applications or joint optimizations that either leverage an existing model in new ways or even bring together multiple models
At this point, accountability and ownership of the data and AI project should move toward the team best suited for the next phase.
Is the current model clearly solving the most important problem for the business? Is there room to improve with statistics and framing? Or does the underlying infrastructure and technology need to become more sophisticated?
When the value comes from refining the business problem, data scientists and/or product managers should own the work.
When the value comes from the data and features or the modeling approaches, data science and/or engineers should own it. It depends on the organization’s size and structure (more on that in the next section).
Whichever team is in best charge of the iterative process, making ownership clear at this stage is essential to hold them — and their leadership chain — accountable for the project’s success.
**Making ownership clear is especially important at larger organizations, which inherently require clearer reporting lines of accountability **vs. a startup operating with an “all hands on deck” mentality.
Data and AI ownership at small vs large organizations
The way data science and engineering organizations operate vary immensely depending on their company’s size — and so does the right answer to the ownership question.
**At very large companies, engineers should be accountable for data and AI projects on established use-cases — because that’s what the scale and complexity of their infrastructure demands. **
At massive, mature organizations like Meta or Google, where teams work with billions or even trillions of data points, ML tasks are explicitly owned by engineering.
 Photo by Sinjin Thomas on Unsplash
Photo by Sinjin Thomas on Unsplash
For example, take an ML product as wildly successful and important as Facebook’s newsfeed. Engineers are responsible for keeping the newsfeed performing at scale and for iterating on the core data and models elements underneath it. Data scientists at Meta aren’t working on the core feed algo, but (important) adjacent pieces like metrics and experimentation. They may also work in adjacent research science organizations that look at entirely new modeling approaches — but once those are translated into viable projects, they’re tackled and owned by engineering.
**Smaller companies face different challenges, usually around determining what business problems are meaningful, and what data is available to solve them. **
For example, at a growth stage startup, you first have to determine what to work on. Is fraud even an issue that’s worth focusing on? If you think so, what kind of data do you have to indicate fraud? Is it clean and reliable?
In these exploratory cases, data scientists can truly shine — prototyping models quickly, demonstrating the possible impact, and partnering with engineering to productionalize and scale.
This is when business leaders who are trying to move fast and execute exactly what they’ve done before run into trouble. Remember that hotshot engineering director from Google you brought in as VP of Engineering at your Series C startup? They’re going to be surprised and frustrated that engineering doesn’t own data and AI from end to end. And you’re going to need to help them think from first principles to figure out what’s right.
How to address data and AI ownership
Now we can see why this ownership question is so complex: it’s dynamic. As your data and AI use case matures and your company’s infrastructure grows, different teams will need to take on — and give away — accountability and ownership.
Clarity here is important, and that clarity can be painful.
Getting to the right place isn’t an easy cultural shift, but you can take specific steps to help improve collaboration and quality of work at every stage.
1. Think deep about where the value comes from
In the earliest stages of a new data and AI project, you need those three skill sets — business, modeling, and engineering — working in tandem. Make sure you have the right people in the right seats to own their respective parts of the project, and give them the resources and motivation to collaborate well together.
For more mature use cases, it makes sense to specialize based on what will actually drive improvement. And make sure ownership is clear so that no team is shrugging off accountability or not taking the bigger picture into account as they lead the iterative process.
2. Hold data science to a high standard
Data science and software engineering are both incredibly important to the success of your data and AI projects — and should be held to equal standards. Instead of letting data scientists get away with handing over spaghetti code and expecting engineers to clean up their mess, implement engineering best practices to improve the quality of their deliverables. Use Git to manage and version code, and conduct QA and code reviews within the data science org.
3. Invest in infrastructure to unlock collaboration
When data scientists work exclusively in notebooks on their local laptops, it’s hard to achieve the visibility and collaboration you need to drive success. It’s impossible in that world for an engineer to weigh in on – or even learn from – their work. Similarly, if engineers don’t invest in infrastructure that makes it easy to deploy and serve models, then data scientists are themselves behind a wall.
While there’s no silver bullet of technology to solve these problems, a wide variety of tools like Amazon Sagemaker, Google Vertex, Databricks ML, and AzureML all have offerings to help data scientists and engineers collaborate more effectively.
 Photo by Viswanath V Pai on Unsplash
Photo by Viswanath V Pai on Unsplash
The good news: it won’t always be this hard
The entire process of how data and AI work gets done is getting easier.
As the approaches for tackling recurring problems like personalization, forecasting, and fraud detection become more established, it’s becoming easier for engineers to take on more of the framing and modeling work. Similarly, as off-the-shelf infrastructure gets stronger, then the engineering challenges get simpler and can be tackled by data scientists.
AI-powered technologies are emerging fast, and much of this work can now be shifted to tools instead of people. The best teams are looking for modern tools that do the work for them. That will lead to more data and AI projects that drive results.
Two years on: AI data agents are a new participant
Since we first wrote this in early 2024, the ownership question has gotten more interesting — not simpler — because there’s a new participant on the team: the AI data agent itself.
For exploratory analysis and the recurring analytical questions that businesses ask over and over, AI data agents can now do much of what used to require a dedicated data scientist or analyst. At Delphina, we’re seeing business teams across marketing, sales, finance, operations, and customer success query their data directly with an agent — getting reliable, multi-factor analyses without the data-science-to-engineering waterfall ever entering the picture. Many of our top users are executives, including multiple CEOs, who couldn’t touch their company’s data before.
The three-legged stool doesn’t go away — somebody still needs business expertise to frame the right questions, statistical thinking to validate the answers, and engineering to keep the infrastructure running. But the agent now takes on a meaningful share of the modeling and analysis legs for a large class of recurring problems. And the AI-managed context layer that the agent runs on — the institutional knowledge about what data means, how metrics are defined, and which business rules apply — becomes a first-class asset that data teams own and maintain.
Practically, this shifts the ownership math in a few ways:
-
Business teams own more of the day-to-day analytical work, because they can self-serve.
-
Data scientists move up the stack — they own the harder problems (causal analysis, new modeling, custom applications) and the context layer that keeps the agents accurate.
-
Engineering ownership for established use-cases still applies — but a lot fewer use-cases need a dedicated engineering team to begin with.
If you’re thinking about how AI data agents fit into your organization’s ownership model, write us at info@delphina.ai or book a demo.