

When I (Duncan) was on Uber’s Marketplace team, we would (semi) joke that we were lurching from crisis to crisis.

Our dozens of core machine learning products directly controlled billions of company dollars — targeted promotions, surge pricing, driver incentives, ETAs, pool matching, upfront rider fares, subscription upsells, the list goes on. We lived in paranoia that these were fundamentally broken in a way that would sink the business.1
Every week brought a new potential Data Science Disaster. The turmoil would always start the same way: someone would find something suspicious in the data. It might have been a spike in our internal metrics like “zeros”, which measured riders who opened the app and didn’t see any cars available. Were we under-surging and losing riders because of poor reliability? Had we deployed too many rider promos? The wrong driver incentives?
Or it could have been a tweet — perhaps a celebrity saw a fare that seemed high, and then they walked 20 feet and the price changed materially — and of course screenshots went viral and started spiraling.
Inevitably, this would happen at 7pm. Our teams at HQ in SF would be starting to grab in-office dinner and maybe an uBeer; data on the evening rush would have landed for all of our key markets; and meanwhile, our non-tech colleagues on the East coast would be logging back on for the late shift. As soon as there was smoke, uChats (Uber’s internal messaging system) would start firing and a whirlwind of analysis would get kicked up, with “jams” set up that evening to dig in or tech reviews scheduled with leadership for the next day. Most of the time we wouldn’t find a real problem, but sometimes we would — resulting in urgent code diffs, roadmap shifts, and sometimes unexpected reorgs and abrupt departures.
It was intense, partly because Uber’s culture was intense. But as I reflect back, I realize it was intense because data and AI work is super intense.
Archimedes once said that given a lever long enough, and a place from which to stand, he would move the world. AI can be the lever that moves the world — when it works well, it delivers incredible, transformative value. But the lever is only as good as its weakest fibers. And when AI is even merely mediocre, it can snap back and slap you in the face.

This is different from most tech (and non-tech) functions, which can tolerate things that aren’t quite perfect. Mediocre product management, mediocre engineering, or mediocre finance aren’t good, but they are often tolerable.
But the returns to quality in AI are highly nonlinear. Great AI is game changing, while mediocre AI is a whole other beast — and it’s downright dangerous. Here’s how we think about it:
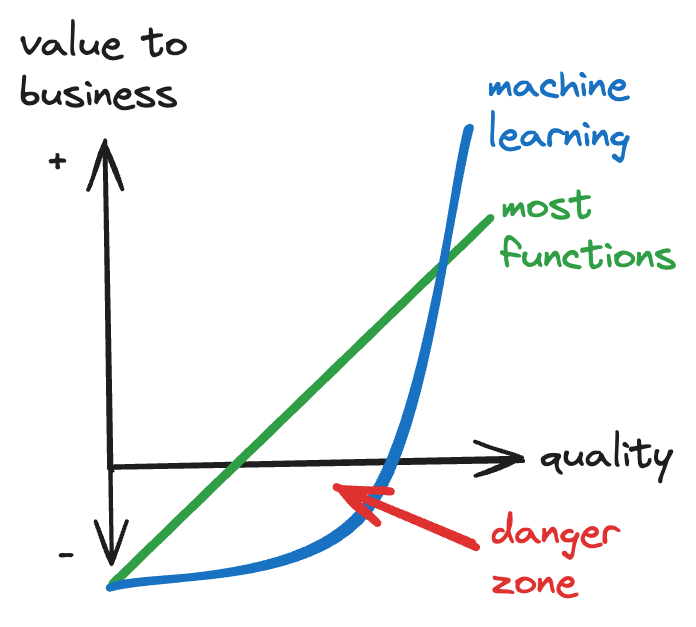
The Danger Zone is the area of mediocre quality in AI: it looks ok but it isn’t. It wouldn't be great but would be tolerable in most functions. And it can do tremendous damage to your business.
Why mediocre AI is especially destructive
As you’re reading this, you might be saying, Yeah, mediocre AI can be bad — but so can mediocre work in any area. We’re going to try to change your mind. We believe that mediocre AI is uniquely dangerous for three reasons:
1. Massive scale amplifies missteps
AI operates on a scale unlike most other business functions. A single model can make millions of high stakes decisions every hour, which means that even minor flaws can have significant consequences.
Consider an ML model that an airline uses to set prices for flights. That model could price billions of dollars of flights each year. The model literally decides the firm’s revenue.
At that scale, the difference between good and bad could be staggering. If things go well the model might generate hundreds of millions of dollars of incremental profit. Or, a subpar model could easily incinerate the same.
It’s now common for AI to be powering dozens of critical applications across the enterprise — from deploying marketing budgets, buying and managing inventory, setting work schedules, blocking fraud, and managing customer support — in each of these, the opportunity is big in absolute terms but the margin for error is small. The system needs to get it right, else things can go very wrong.
2. AI systems are opaque & outputs are hard to monitor
AI systems are made up of many different parts, each operating with minimal human oversight, and these systems can be deceiving.
On the surface, everything might look like it “works” — data gets ingested, predictions are made, decisions are set — but it could be on fire inside. The system could be optimizing for something you didn’t really want, like clicks instead of quality. Worse yet, you did intend to optimize for clicks, but the clicks data could simply be broken — and you didn’t know it. And so, unbeknownst to anyone, the system’s outputs could be burning a hole in your business.

AI systems typically deliver hyper-targeted predictions and answers, and it’s this targeting that makes them so valuable — but it’s also this targeting that makes it impractical-to-impossible for any human team to monitor the outputs with precision. There’s just way too much data coming out of the system to actually review and understand.
The difficulty inherent in monitoring AI systems is especially troubling in life-or-death stakes situations like in medicine, where AI is increasingly being used to diagnose diseases and determine treatment plans. That isn’t to say we shouldn’t try to bring AI into these contexts — the positive impacts of AI on healthcare can literally be life-saving — but we have a lot work to do to make sure we can detect problems. (Needless to say, this is getting even harder in the age of generative AI!)
3. There aren’t established ways of doing it “right”
Data and AI work is relatively new, and there simply aren’t that many experts in the field. Most business leaders lack AI expertise — and data scientists lack business experience.
This is hard for both sides: leaders find it difficult to critically evaluate AI systems and methodologies. They might not even know what questions to ask, and might not recognize issues like overfitting or biased training data.
At the same time, since the field is new and specialists are in high demand, many data scientists are junior. These freshly minted PhDs excel in statistics, but they aren’t taught how to build production AI systems in school. They also haven’t had the chance to develop business acumen and are figuring it out from scratch every time.
Overall, this makes it way too easy to inadvertently make major mistakes — which would be quickly caught in more mature functions.
Signs you're in the danger zone — and what to do about it
It can be hard to know if you’re in the danger zone, because for AI, it’s just spitting distance from a panacea of transformative impact. The scariest part of the danger zone is where you think everything checks out but the reality is it doesn’t. Making it to the happy place in the far right tail is about getting ALL of the pieces right.
In our experience, success requires having crisp, affirmative (and correct) answers to each of the following:
- Do you know what you are trying to solve for?
- Do you have high quality data?
- Have you built features that capture the key patterns in our data?
- Have you chosen appropriate models – sufficiently flexible to capture the patterns, but not so flexible as to overfit?
- Do you have rigorous training, testing, and validation procedures?
- Do you run careful, long-term experiments to measure impacts?
- Do you have production monitoring in place?
- Do you have robust and scalable pipelines and infrastructure to train and serve your models?
- Have you revisited all of this recently, since what worked a year ago might be broken now?
Perhaps most importantly, do you have a culture of curiosity and inquiry, where it’s rewarded to question whether the pieces make sense? There will inevitably be problems — so you need a team that will dig in.
At Uber, one of our data science values was “As simple as possible, but no simpler”. Our recommendation is to instill that approach — and a relentless focus on quality — to every part of the AI workflow. That's how you end up on the happy path.

Shrinking the danger zone: critic agents and AI-generated evals
Since we first wrote this in 2024, the danger zone problem has only gotten more acute. AI data agents that answer business questions directly are even more opaque than the ML models we described above — a single LLM-driven agent can produce confidently wrong answers at scale, and the "looks ok but isn't" problem is harder to catch because the outputs read fluently.
This is exactly why we built two specific pieces into Delphina:
-
A critic agent that independently reviews each answer before it’s shown — checking the logic, the SQL, the data joins, and the interpretation against the institutional context layer. The critic catches mistakes the answer-generating agent makes, the same way a senior data scientist would catch a junior analyst’s mistakes in a code review.
-
AI-generated evals that continuously test the system against ground truth as the underlying data evolves. Where it used to take a quarterly audit to discover that a model was operating in the danger zone, evals catch drift in days.
Neither makes AI infallible. But together they shrink the danger zone substantially — the gap between "looks ok" and "actually ok" is much narrower when you have automated systems checking the work continuously, rather than waiting for a tweet to go viral or a metric review to surface the problem.
The Uber-style 7pm uChat fire drill hasn’t disappeared from the world. But for business teams using AI data agents, it can happen far less often.
If you’d like to talk about how to keep your data and AI work out of the danger zone, write us at info@delphina.ai or book a demo.
1. With Uber’s market cap at $140B as of writing, I think it’s safe to say that we did not in fact sink the business.