This post is authored by Delphina engineer Thomas Barthelemy. After completing his MS in CS at Stanford, Thomas joined Coursera as employee 40 and saw the company to IPO at over 1,000. Needless to say, he has a lot of experience — and a lot of thoughts — around testing at a fast-growing tech company.
In all companies I’ve encountered, there’s a lot of virtue-signaling around automated testing. When the question comes up, we say with confidence that we really should write tests. But, then with a sigh, we remark there is never enough time and nobody is perfect, and we hardly ever write tests…
Why the disconnect? Everyone knows there are compounding benefits of automated testing**.**
The problem is that most engineers don’t understand how to write high-ROI unit tests.

Recently, our team here at Delphina sat down for a brown-bag session about testing. We shared perspectives and struggles, zeroed in on our own philosophy around testing, and discussed how LLMs are changing the game. Here’s a peek behind the curtain into how we think the traditional model is broken — and what the way forward might look like.
Recapping the (somewhat) obvious: why testing matters
Bugs are costly for engineering teams. When customers run into them, bugs degrade trust in the product (at best) and cost the customer financially (at worst). At Delphina, we’re building AI data agents on top of an AI-managed context layer, and the most pernicious bugs may silently manifest as a drop in agent accuracy or model performance. Imagine a bug quietly degrading performance over months! You could lose new customers or cause customers to churn without anyone putting their finger on it.
Even though “testing is good” is hardly a controversial opinion, it’s worth getting concrete about why testing matters. Testing helps organizations accomplish two primary goals:
- Validating new code. Testing is one of the fastest ways to validate that your code is working. I’m a stickler when it comes to automated testing because I’m lazy when it comes to manual testing. When I was a backend developer, for instance, it was much easier to write tests than to spin up the UI and walk through various user flows to validate my service was working as expected. Today, this virtuous laziness is still the proximate motivator for including tests in my pull requests.
- Safeguarding against regressions. Avoiding regressions is where testing drives the most organizational value. As a codebase becomes more complex, we increase the risk that an engineer introduces a bug due to incorrectly or incompletely deducing how the system will behave in response to a code change.
Of course, I’m a big fan of managing your overall system complexity. I recommend John Ousterhout’s A Philosophy of Software Design to anyone who’s interested. But complexity grows inevitably, so testing is a critical safeguard.
With good testing in place, we can catch bugs before the code lands or, ideally, while we’re implementing new code. This makes them much easier to fix. When weeks or months go by before catching a bug, there’s a good chance the author of the code won’t remember the context — if they’re even still around to work on it.
Implementing an effective testing strategy is uniquely challenging for a startup. Testing is resource-intensive, requiring significant time and effort from already overloaded engineering teams. Startups need to be laser-focused on efficiency, and sometimes people think of automated testing as a luxury that can come later (if there is a later!). But I believe the need for robust testing starts on day one, even as other priorities compete for attention.
So why do startups often forgo automated testing? Because teams do not know how to create high ROI tests.

How to create high-ROI tests
Let’s break ROI down into the return and investment:

Not super surprising, right? But here are a few non-obvious implications:
- The right goal isn’t 100% test coverage. Some lines are just not that important to your business. Other lines are unlikely to be broken — say, they are rarely touched, or they are too trivial to spot-check, or they are already well-validated by the static type checker.
- Tests that last a long time are way more valuable. A test does not guard against regressions if the next time the code is touched, the test needs to be deleted and rewritten. This is the reason it’s often a good idea to hoist a test up to the level of the external interface rather than writing unit tests for internal functions.
- Higher-level tests can probably cover more lines per test. So, end-to-end tests cover more than integration tests, which in turn cover more than unit tests.
- Higher-level tests are probably more costly to run, and therefore worse at covering a broad set of configurations. If you’re building a web app, you could write all your tests in the form of selenium tests that click through the UI – but this would probably be annoying to set up and extremely slow to run.
- Tests that are too high-level may tell you that something is wrong, but not what. Without more granular testing, you could spend hours trying to understand why the system behaved a certain way. This is especially true if the behavior under test involves complex state management.
Build a test Trophy, not a Pyramid
The de facto testing portfolio that most people think about is the Testing Pyramid, which emphasizes writing many more unit tests because they run much faster. People have mistaken this as a law of software engineering: they must write many unit tests, even if higher-level tests can be quite fast.
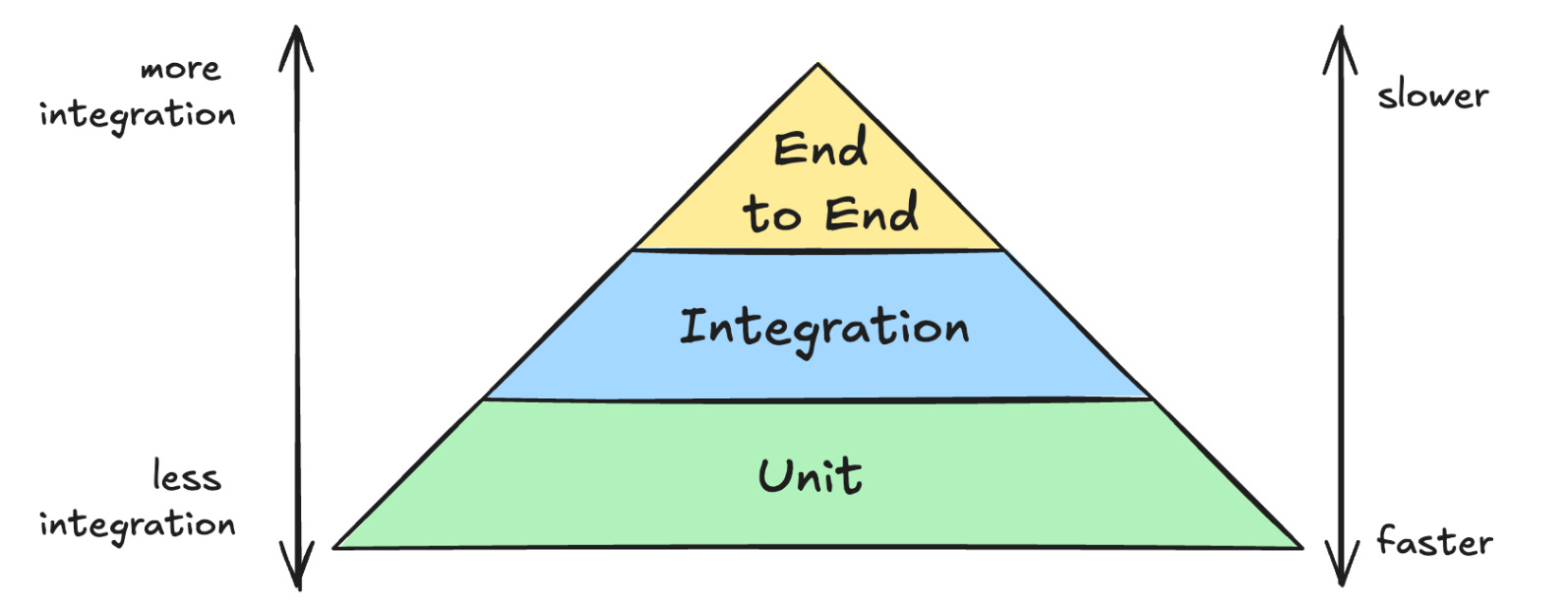
However, if you can run integration tests fast, a better option is the Testing Trophy, which is what we’ve adopted at Delphina.
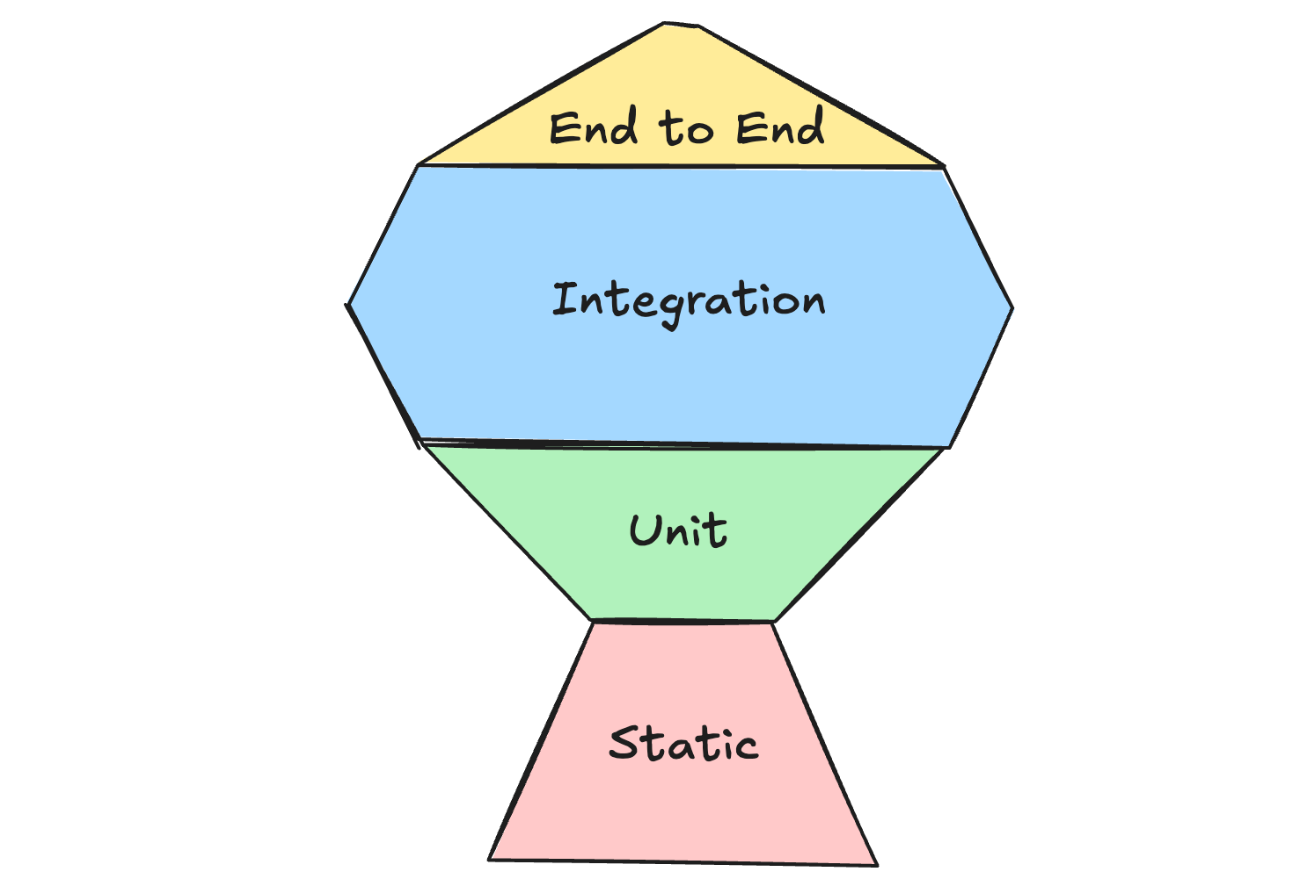
Under the trophy framework, our testing portfolio looks different — starting with the inclusion of static validation in the testing portfolio. From there, we include:
-
Substantial static type checking: pyright for Python and application code in typescript
-
Some unit tests for critical units or those with fairly complex logic — otherwise, we test that functionality at a higher level to improve efficiency.
-
Mostly integration tests since they have the right balance of high ROI (covering lots of units and lots of behaviors) and low cost or performance penalties.
-
Some end-to-end tests since they’re incredibly useful, but have to be limited due to cost.
Especially in a startup environment, where speed is paramount and resources are limited, this balanced approach helps us optimize for velocity, minimize regressions, and maintain our pace over time.
That said, we always keep in mind that a robust testing portfolio doesn’t mean total coverage. That’s why we monitor subtle, related signals — like how much time we’re putting into fixing bugs in code that’s already landed. And in our postmortems, we don’t just ask *How did the bug happen? *But also, *How did this bug get through our testing harness? *Paying attention to these kinds of signals can help us identify problem areas that need to be addressed.
Whether the Pyramid or the Trophy is best for your startup is for you to decide. The key takeaway here is to be mindful about your testing portfolio — the mix of unit tests, integration tests, and end-to-end tests you invest in — and be open to updating your strategy over time.
Looking ahead: the implications for testing LLMs
But what about LLMs? As more organizations — both startups like our own as well as larger companies — rely on LLMs as part of their products and pipelines, those models also have to be included in our testing portfolios. Two challenges caused by LLMs are that:
-
LLM behavior is nondeterministic
-
Performance of the system might drift over time, even if we don’t change our code
This is still very new territory for everyone, but here are a few ways we are testing LLMs effectively:
-
Use test doubles while validating the correctness of our code: One approach is to create a "fake" version of the LLM for testing purposes. This can be a simplified model that mimics the basic behavior of the full LLM, but runs faster and more consistently. While this won't catch all issues, it can help identify basic integration problems without the cost and variability of calling the actual LLM.
-
Pin LLM version: Where possible, we can use pinned versions of LLMs for testing. While this doesn't solve all problems (the underlying model might still change), it provides a more stable baseline for our tests.
-
Use systematic benchmarking to validate overall performance: This can be helpful for (a) identifying cases where an LLM’s behavior may drift in a way that hurts our system performance; and (b) identifying cases where our code changes interact with the LLM behavior to drop performance.
Ultimately, testing LLMs requires another paradigm shift in how we think about testing. We're moving from a world of deterministic, correctness-focused testing to one that's more akin to performance testing or monitoring. That means we're less concerned with whether an LLM produces an exact expected output — as measured by a traditional pass/fail test — and are more focused on whether it's performing its function effectively over time.
So our "tests" might look more like ongoing benchmarks, with alerts triggered when performance dips below certain thresholds. Or we might focus on downstream metrics, like customer satisfaction scores or resolution times for an LLM-powered customer service automation.
As with our overall testing strategy, the key is to be mindful — of the balance of our portfolio, of the inherent trade-offs, and of the actual ROI our tests deliver.
We’re hiring at Delphina – if this is exciting to you, don’t hesitate to reach out!